Exploring the Demographics of US Congressional Districts in R
I recently created a few datasets to facilitate analyzing the interaction between demographics and political party affiliations of US Congressional Districts. My goal was to create this graph: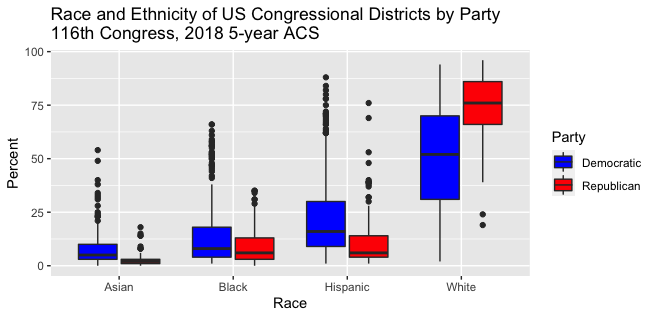
I added this data to Choroplethr and pushed the new version to CRAN. This post walks you through using these datasets, the analysis I did, and the nuances behind the data.
Getting Started
The first step is to download the latest version of Choroplethr. Type the following at the R console:
install.packages("choroplethr")
library(choroplethr)
packageVersion("choroplethr")
# [1] ‘3.7.0’
This new version is 3.7.0, and your console should output “[1] ‘3.7.0’”
Technical Note
This analysis is limited to the 435 Voting Members of the House of Representatives who were elected to the 116th Congress in 2018. All demographic data is from the 2018 5-year American Community Survey (ACS).
New Data
?congress116.regions
Each time I start working with a new geography I like to create a data structure with a naming convention of <geography>.regions. These data structures always have a column named region which contains the “official” name of that region, and other columns that contain metadata about that region:
data(congress116.regions) head(congress116.regions, n=10) region state.name state.fips district.number 1 0101 alabama 01 01 2 0102 alabama 01 02 3 0103 alabama 01 03 4 0104 alabama 01 04 5 0105 alabama 01 05 6 0106 alabama 01 06 7 0107 alabama 01 07 8 0200 alaska 02 00 9 0401 arizona 04 01 10 0402 arizona 04 02
Here region is a 4-character number (i.e. there is always a leading 0). We also have the name of the District’s State, its FIPS code and District Number.
As a rule of thumb, the numbering of Districts starts at “01”. The exception to this is when a state has only one Voting Member (such as Alaska, shown above). Then the District Number is “00”.
?df_congress116_demographics
I also added a data.frame that contains a handful of demographic statistics about each Congressional District. The naming convention for these data structures in Choroplethr is df_<geography>_demographics. So here the structure’s name is ?df_congress116_demographics. The data comes from the 2018 5-year ACS.
data(df_congress116_demographics) head(df_congress116_demographics) region total_population percent_white percent_black percent_asian percent_hispanic per_capita_income median_rent median_age 1 0101 706503 65 27 1 3 26318 637 39.6 2 0102 680575 62 31 1 4 25511 566 38.5 3 0103 706705 68 25 2 3 25172 524 38.4 4 0104 683391 84 7 1 6 23865 430 40.8 5 0105 714145 73 17 2 5 30809 565 39.7 6 0106 703715 76 15 2 5 34527 766 39.0
Note: this data comes from a new function I wrote called ?get_congressional_district_demographics. If you want to get the same data from other years or surveys, use that function.
?df_congress116_party
The purpose of this analysis was not just to look at demographic statistics, but to see the interaction between demographics and party affiliation. I scraped political party data on the members of the 116th Congress from Wikipedia and stored it in the data.frame ?df_congress116_party:
data(df_congress116_party) head(df_congress116_party) region party state.name district.number member 1 0101 Republican alabama 01 Bradley Byrne 2 0102 Republican alabama 02 Martha Roby 3 0103 Republican alabama 03 Mike Rogers 4 0104 Republican alabama 04 Robert Aderholt 5 0105 Republican alabama 05 Mo Brooks 6 0106 Republican alabama 06 Gary Palmer
Visualizing the Data
ggplot2 requires all your data to be in a single data.frame. So we start by merging ?df_congress_116_demographics with ?df_congress116_party:
df = merge(df_congress116_demographics, df_congress116_party)
The code to create the graph at the top of this post is actually quite complicated. I encapsulated it in the new function ?visualize_df_by_race_ethnicity_party:
library(ggplot2)
visualize_df_by_race_ethnicity_party(df) +
ggtitle("Race and Ethnicity of US Congressional Districts by Party\n116th Congress, 2018 5-year ACS")
We still need to set the title manually, because the function has no way to know the geography or year of the data.
Explanation
When I show the above chart to my friends who have studied Data Visualization they say “Wow – that’s pretty dramatic!” However, my friends who have not studied Data Visualization are confused by it. I would like this analysis to be understood by everyone, so I’ll take a moment to explain the chart.
The chart shows a series of Box Plots. A Box Plot helps you understand how numbers are distriburted.
- The “box” shows the 25th to 75th percentiles.
- The horizontal line in the middle of the box shows the median value.
- The vertical line shows the minimum and maximum values.
- The circles are statistical outliers.
Example
Now that you know what a Box Plot is, we can walk through a specific example of how it helps us understand this data.
Each Congressional District has some percentage of residents who are White. That number must be between 0 (no White residents) and 100 (all residents are White). This chart divides all Congressional Districts into two groups based on the Political Party that each District voted for. Then it creates a box plot to visualize the percent of residents in each group that are White.
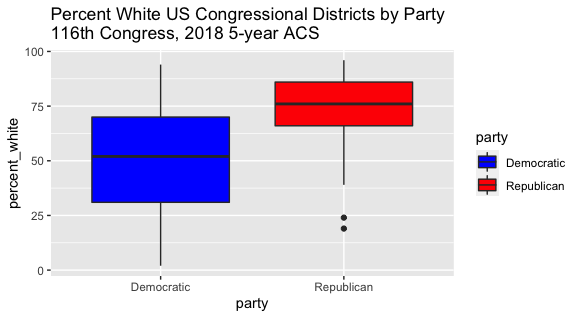
ggplot(df, aes(party, percent_white)) +
geom_boxplot(aes(fill = party)) +
scale_fill_manual(values = c("blue", "red")) +
ggtitle("Percent White US Congressional Districts by Party\n116th Congress, 2018 5-year ACS")
The result here is quite dramatic. For Democratic Districts, the median value was 52% White. But for Republican Districts, the median value was 76% White. The median value for Republican Districts was higher than the 75th percentile for Democratic Districts. This Box Plot alone demonstrates that in the 116th Congress, the Democratic and Republican Districts had very different demographics. The other plots simply reinforce that point.
How You Can Help
I often hear from Choroplethr users who love the project and want to help it succeed. There are three ways you can help.
Funding
The best way to help Choroplethr grow remains with funding. I estimate that it will take about a month to move all the Choroplethr maps from the old “Fortified Data Frame” format to Simple Features. If you know of an organization that can fund that work, then please contact me.
Review my Work
Another way you can help is by reviewing my work. Choroplethr is currently a side project, which means that (a) I don’t have any QA staff double checking my work and (b) I don’t have any clients double checking my work. The worst case scenario is that my work contains an error, and that the error impacts someone’s analysis.
There are two things in this release that I would like reviewed:
- The code for getting the Congresssional District party affiliations (i.e. generating ?df_congress116_party), which can be found here. As you will see, I seem to have stumbled upon a bug in how RVest, R and/or RStudio handle when scraped from Wikipedia. I detail the issue in the code, as well as my workaround.
- The code for getting the demographic statistics for the Congressional Districts, which can be found here. There seems to (arguably) be a bug in either TidyCensus or the data the Census API returns when you request demographic on Congressional Districts. I detail the issue in the code, as well as my workaround.
Redistricting Experts
?get_congressional_district_demographics currently returns eight demographic statistics for each District. These are the same eight variables that I chose, almost at random, five years ago when I started working on Choroplethr.
I would like to hear from Redistricting experts on the tables that they use in their work. I think it would be valuable to have Choroplethr grow into an open source tool that allows people to explore Redistricting. But to do that, I need to talk to subject matter experts. If you can help with this, then please contact me.