All posts by Ari Lamstein
Python Census Explorer v1.2.0: Census Tracts
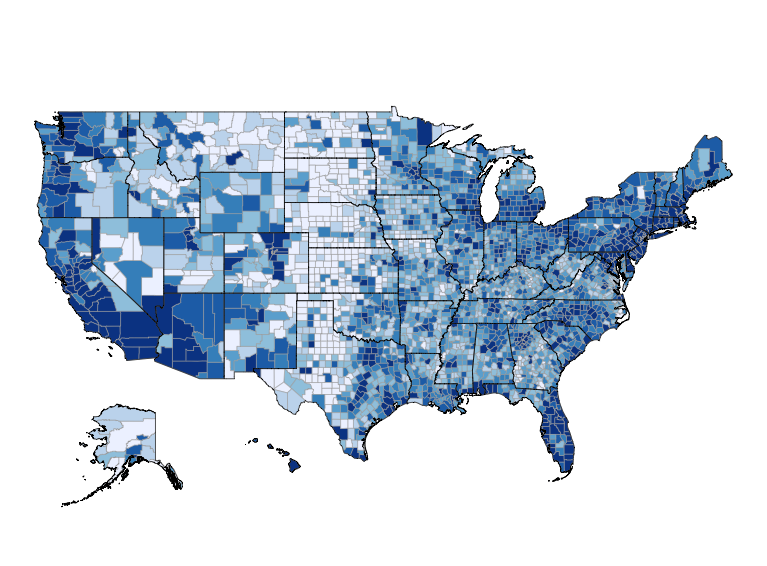
I just updated my Python Census Explorer app. You can view the new version by visiting census-explorer.streamlit.app or clicking the image below: Major Change and Project Goal My long-term goal with this project is to explore how neighborhoods across the country changed during Covid-19. Previously the app showed selected demographics of all counties in a […]
Continue readingCreating Interactive Choropleths with Streamlit
Last week I published version 1.0 of my first project using Streamlit. The app is a simple “Census Explorer” that lets users select a state and demographic statistic, and then publishes the data as both a table and a map. Here is how version 1.0.0 of the app looked: Unfortunately, this map suffers from a […]
Continue readingPython Census Explorer: v1.0 is now Online!
A few weeks ago I wrote about my desire to build a “Census Explorer”-type app in Python. My thinking was not that the world needs yet another website to browse Census data. But rather (a) I was at a point in my “Data Science with Python” journey where it made sense to take on a […]
Continue readingBuilding a Census Explorer in Python: Part 1
One of my career goals is to get as fluent with Python as I am with R. Since I don’t use Python at work, my efforts so far have focused on online courses and weekly exercise services. Courses came first (you need to learn the fundamentals somehow, after all). Then came weekly exercises (that’s where […]
Continue readingReflections on Learning Pandas
One day last year I woke up with the thought: I want to know Python as well as I know R. I like R, and happily use it every day at work. But I also have the impression that an entire ecosystem in the data world has sprung up around Python. It appears that this […]
Continue reading