Reader Questions about Analytics Engineering
Last week I announced a new focus for my blog: codifying my thoughts around the new role of Analytics Engineering. The post led to some interesting exchanges with longtime readers. I thought that two of these questions, along with my responses, might interest a wider audience, so I am copying them here.
Q1: How does “Analytics Engineering” compare with “Data Engineering”? Are they the same thing?
At the highest level, you can probably consider these job titles to be interchangable. When you get into the details, though, there are meaningful differences.
Both titles refer to software engineers. That is, the primary responsibility for both is writing and maintaining software. This is in contrast to a Data Analyst or Data Scientist, where the primary responsibility is “saying something about data”.
Data Engineer is a more established position. People in these positions typically work with “Big Data” stores such as Hadoop and Spark. They use data pipeline tools such as Airflow. Many of these jobs involve working on a team with a large number of engineers, where you might have little or no contact with analysts and scientists.
Analytics Engineer is a newer role, so the responsibilities can vary more from company to company. They tend to require advanced knowledge of SQL but not experience with Big Data stores. They also have regular contact with Data Analysts and Data Scientists, and write custom code for them.
I recently spoke with a manger looking to fill an Analytics Engineer position. He described their need this way: “We have a team of 6 data scientists who have written a lot of code. They are great scientists / statisticians, but not great software engineers. They’re now spending too much time maintaining this code. I want a ‘real’ software engineer to come in and take ownership of all this code. That way the scientists can focus more on designing experiments and interpreting data.”
Q2: Tableau Research just published a paper about roles on data science teams. They do not specifically mention “Analytics Engineer”. How does that role fit in?
The specific paper this reader referred to is Passing the Data Baton: A Retrospective Analysis on Data Science Work and Workers. I read the paper and enjoyed it.
One reason I liked it was this quote: “There exists ambiguity and even some contention as to what data science actually is.” When researchers at Tableau say that, then it gives cover to people like me when we say we don’t know what data science is either!
Page 7 of the paper has this table. It attempts to capture both the process that Data Science teams are engaged in, as well as the roles of the members that make up those teams. It describes data science as a 4-step process (Preparation, Deployment & Engineering, Analysis and Communication) with 9 unique roles:
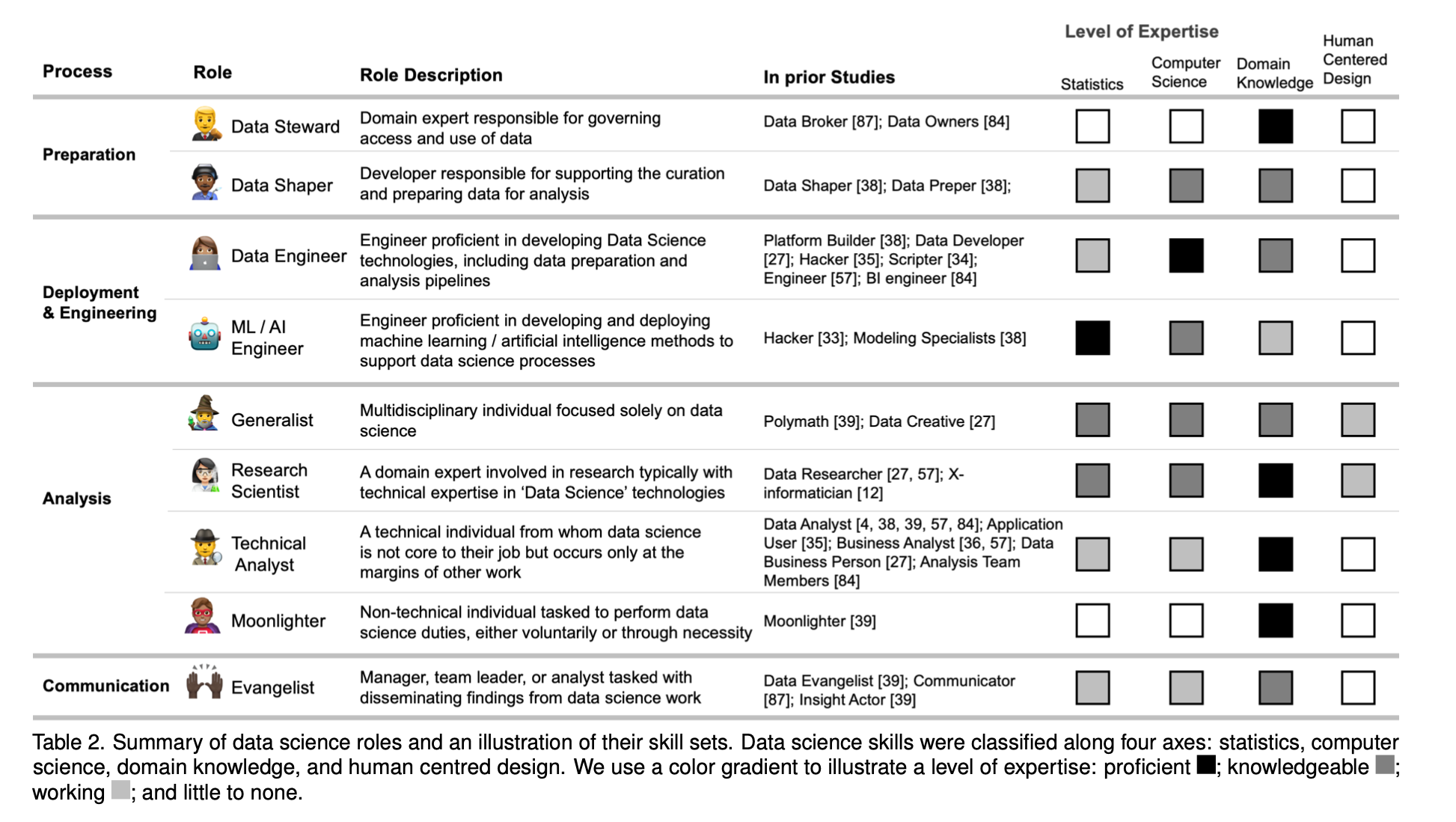
This table lists two types of engineers: Data Engineers and ML / AI Engineers. Below is how they contrast the two:
Data Engineers and Machine Learning / Artificial Intelligence (ML/AI) Engineers primarily work within deployment processes but also engineer systems that facilitate data science work in general. In the terminology of the visualization literature, these roles represent fellow tool builders who, among other things, are capable of developing their own standalone data visualization tools or effectively using charting libraries in various programming languages. Data engineers ensure that artifacts can move seamlessly across data science processes and can scale to changing demands on the system, especially in situations where organizations have massive volumes of data. Data engineers tend to have a stronger background in computer science. ML/AI engineers tend to focus much more on the modeling phase of the data science process and tend to have a stronger background in statistics. Engineers have highly specialized needs of data science and visualization tools.
So where do Analytics Engineers fit into this? Using the lingo from this paper, and the description from my previous answer, I would say “An Analytics Engineer is an engineer that specializes in the Analysis process on a data science team. Like data engineers, they typically have a stronger background in computer science than statistics”.