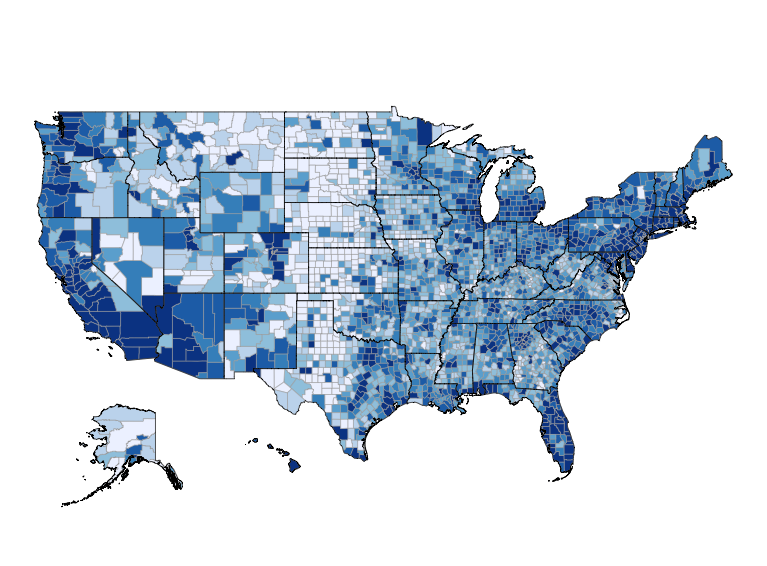
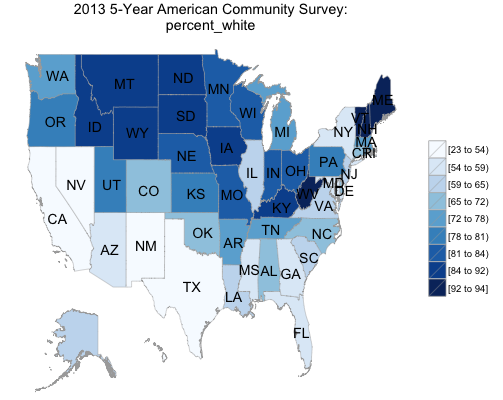
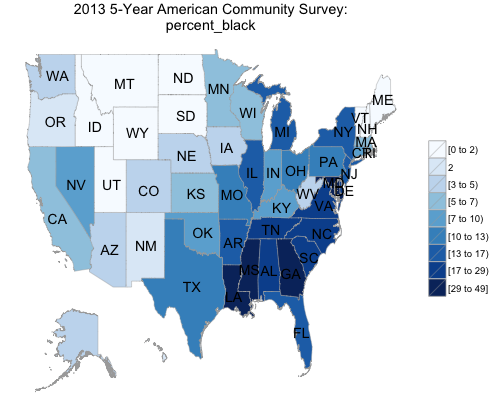
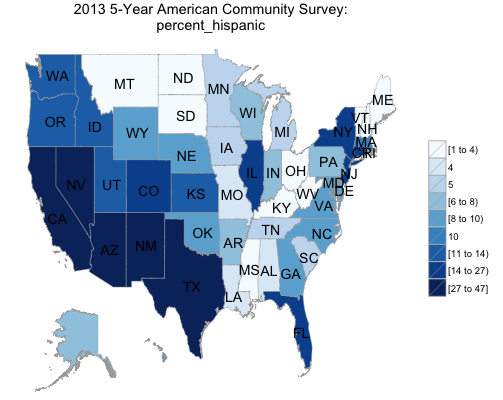
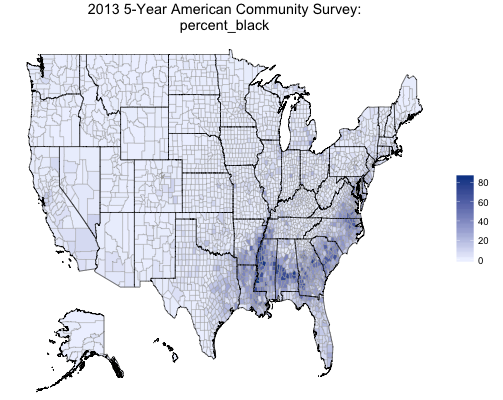

6 comments
The interactive web application is great! I use ACS and Census data to look for associations between disease incidence (the focus of my work) and area based poverty measures, such percent living below the poverty line (at the Census Tract level in San Francisco). I enjoyed reading your piece on the Revolution Analytics blog. Any plans to include census tract level data (rather than zipcode) in future versions of the choroplethr package? Thanks!
Tanya,
Thanks for the kind words! I am interested in the correlations that you describe – do you have a link to any publications about it?
I am indeed interested in drilling farther down. Here is the link to the census bureau’s page on shapefiles for census tracts: https://www.census.gov/geo/maps-data/data/cbf/cbf_tracts.html.
It appears that it there shapefiles are by state, though. So it might not be possible to ship a package that includes the whole nation. Were you just interested in California?
Hi, The url for the exploration app, https://arilamstein.shinyapps.io/choroplethr-3-1-0-shiny-app/, results in a 404.
Unfortunately, you are correct. This post is over a year old, and in the interim my hosting bill for shiny apps became very expensive and I discontinued the service. If you are interested in learning how to create shiny apps like this, I do have a course on it in my Membership site: arilamstein.com/membership.
Hi. I have attempted to install/load choroplethr but R still cannot recognize the new functions, like zip_choropleth_acs. I got my own ACS key too but that didn’t help. R seems to recognize the deprecated functions but tells me I should use the new ones, which it . . . doesn’t recognize. Any advice?
All zip related functions are now part of the choroplethrZip package. There is documentation on the github page for that package. Can you take a look at the documentation on the github page and tell me if that helps: https://github.com/arilamstein/choroplethrZip. What this comment, and other recent comments, is highlighting to me is that I really need to have a separate section on my website for all my open source projects, including up to date documentation. I know that this page was mentioned on a prominent blog recently and so is getting a lot of traffic, but it’s fairly out of date. Sorry to be brief – I’m writing this on a plane and they just announced that we’re descending.