Free R Help
Today I am giving away 10 sessions of free, online, one-on-one R help. My hope is to get a better understanding of how my readers use R, and the issues they face when working on their own projects. The sessions will be over the next two weeks, online and 30-60 minutes each. I just purchased Screenhero, which will allow me to screen share during the sessions.
If you would like to reserve a session then please contact me using this form and describe the project that you want help with. It can be anything, really. But here are some niches within R that I have a lot of experience with:
- Packages that I have created
- Analyzing web site data using R and MySQL
- Exploratory data analysis using ggplot2, dplyr, etc.
- Creating apps with Shiny
- Creating reports using RMarkdown and knitr
- Developing your own R package
- Working with shapefiles in R
- Working with public data sets
- Marketing R packages
Parting Image
I’ve included an image, plus the code to create it, in every blog post I’ve done. I’d hate to stop now just because of the free giveaway. So here’s a comparison of two ways to view the distribution Per Capita Income in the Census Tracts of Orange County, California:
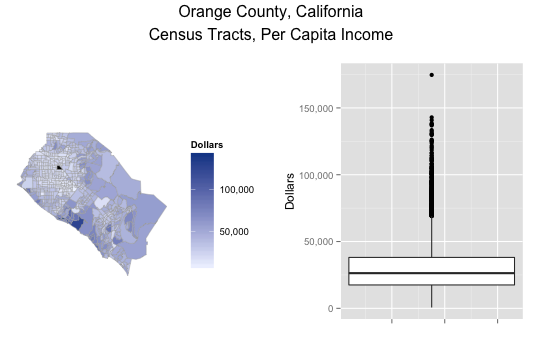
On the right is a boxplot of the data, which shows the distribution of the values. On the left is a choropleth, which shows us where the values are. The choropleth uses a continuous scale, which highlights outliers. Here is the code to create the map. Note that the choroplethrCaCensusTract package is on github, not CRAN.
library(choroplethrCaCensusTract)
data(df_ca_tract_demographics)
df_ca_tract_demographics$value = df_ca_tract_demographics$per_capita_income
choro = ca_tract_choropleth(df_ca_tract_demographics,
legend = "Dollars",
num_colors = 1,
county_zoom = 6059)
library(ggplot2)
library(scales)
bp = ggplot(df_ca_tract_demographics, aes(value, value)) +
geom_boxplot() +
theme(axis.text.x = element_blank()) +
labs(x = "", y = "Dollars") +
scale_y_continuous(labels=comma)
library(gridExtra)
grid.arrange(top = "Orange County, California\nCensus Tracts, Per Capita Income",
choro,
bp,
ncol = 2)